
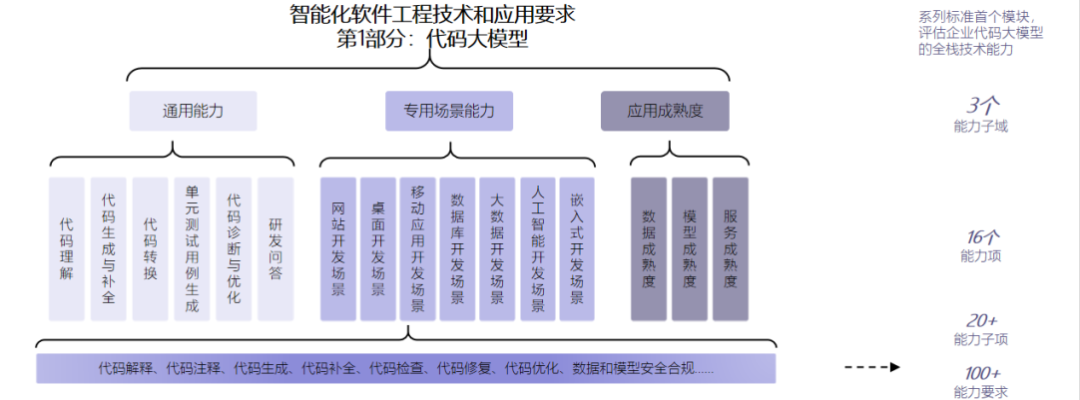
 IT之家注:《智能化软件工程技术和应用要求 第 1 部分:代码大模型》(标准编号 AIIA / PG 0110-2023)标准于 2024 年 1 月 25 日正式发布,该标准由中国信通院与中国工商银行联合牵头发起,涵盖通用能力、专用场景能力和应用成熟度三大部分,包括 100 多个能力要求。 此次验证,依据标准开展,评价指标覆盖 6 大通用能力场景、7 大专用能力场景、3 大服务成熟度,多维度验证研发大模型在研发场景能力和人效优化效果方面的场景丰富度,重点考察研发大模型在代码理解、代码生成和补全、研发问答、单元测试用例生成等方面的能力支持度,全方位评估研发大模型在数据合规性、模型成熟度、服务成熟度方面的应用成熟度。
IT之家注:《智能化软件工程技术和应用要求 第 1 部分:代码大模型》(标准编号 AIIA / PG 0110-2023)标准于 2024 年 1 月 25 日正式发布,该标准由中国信通院与中国工商银行联合牵头发起,涵盖通用能力、专用场景能力和应用成熟度三大部分,包括 100 多个能力要求。 此次验证,依据标准开展,评价指标覆盖 6 大通用能力场景、7 大专用能力场景、3 大服务成熟度,多维度验证研发大模型在研发场景能力和人效优化效果方面的场景丰富度,重点考察研发大模型在代码理解、代码生成和补全、研发问答、单元测试用例生成等方面的能力支持度,全方位评估研发大模型在数据合规性、模型成熟度、服务成熟度方面的应用成熟度。 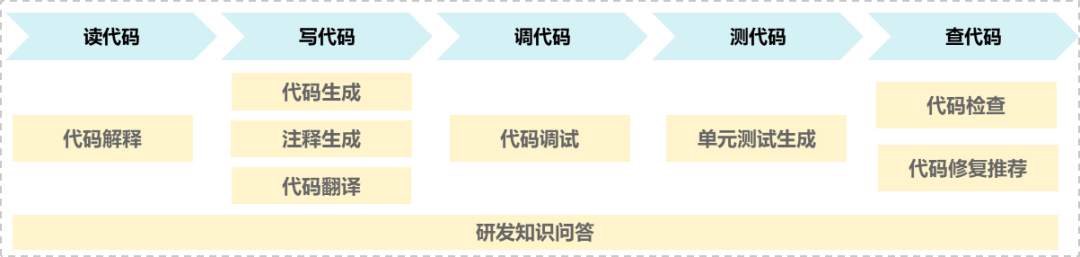 目前,华为云盘古大模型、智谱 CodeGeeX 代码大模型、阿里云 AI 编程助手通义灵码、中国电信星辰政务大模型等首批通过评估,并在全部 100 多个能力评估中表现优秀,获得 4 + 评级。
目前,华为云盘古大模型、智谱 CodeGeeX 代码大模型、阿里云 AI 编程助手通义灵码、中国电信星辰政务大模型等首批通过评估,并在全部 100 多个能力评估中表现优秀,获得 4 + 评级。 
 以阿里云通义灵码为例,信通院评测结果显示:
以阿里云通义灵码为例,信通院评测结果显示:- 在通用能力方面,通义灵码在代码转换、代码检查及修复、代码优化等方面表现突出;
- 在专用场景方面,通义灵码提供网站开发、数据库开发、大数据开发、嵌入式开发等多个场景支持能力;
- 在应用成熟度方面,通义灵码具备较完善的数据合规及数据分类分级机制,且模型稳定性及可维护性表现优异,在模型推理性能、模型服务风险可控性等方面均表现优秀。
原文转自IT之家: https://www.ithome.com/0/774/571.htm