
【摘要】10月11日,英伟达公司和微软公司宣布了他们共同开发的全世界迄今为止所训练的最大、功能最强的单片转换器语言模型,这一语言模型是一个拥有高达5300亿个参数的 AI 模型,称为 Megatron-Turing 自然语言生成模型。
上半年安全咨询服务市场同
相比这两家公司之前分别各自开发训练的也是基于转换器的系统,也就是微软公司的 Turing-NLG 模型和英伟达公司的 Megatron-LM。这次两公司共同开发的 MT-NLG 模型功能强大了许多。MT-NLG 有着分布在105层的较之前三倍多的参数,整个系统更大更复杂。参考一下其他公司的最新的 AI 模型进行对比,可以更直观地了解 MT-NLG 的复杂度:OpenAI 的 GPT-3 模型有着1750亿个参数。
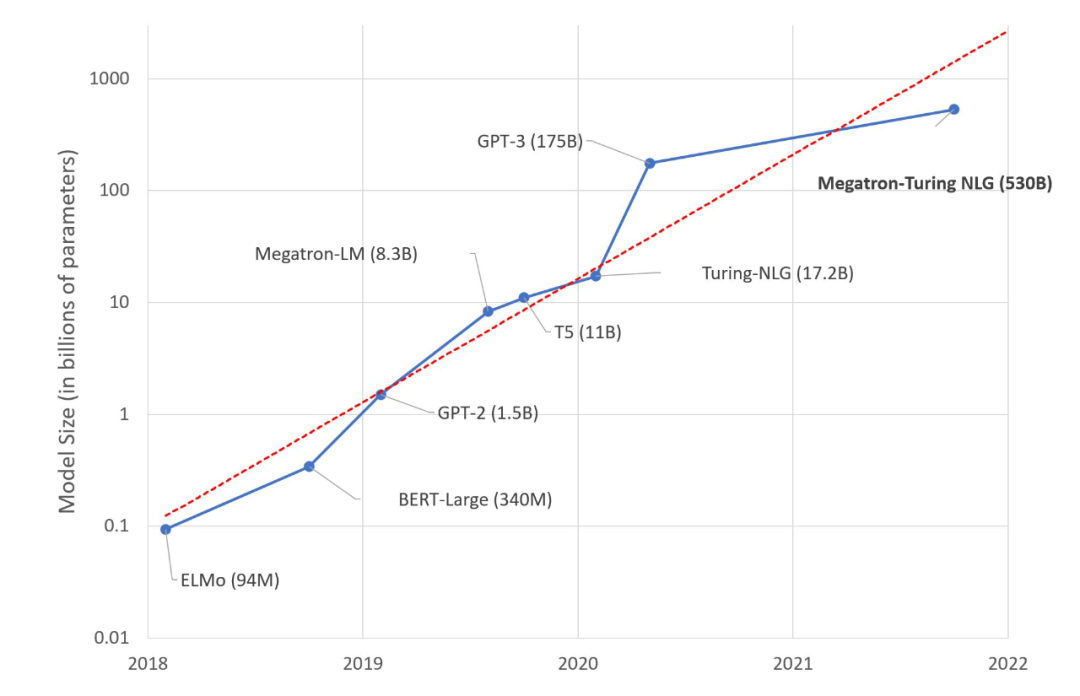
▲图 | 几个著名的自然语言模型的参数数量的对比(来源:英伟达网站)
在机器学习中,参数是从之前的历史训练数据中所学习到的模型部分。尤其是在语言处理领域,参数的数量和复杂程度之间的相关性很高。对于神经网络而言,一般来说,参数越多,系统越复杂通常意味着功能越强大,因为这样系统在训练过程中将会获得更多的训练数据,系统对于语言的理解也会随之更加丰富、细致和准确,甚至获得总结书籍以及完整编程写代码的能力。
与英伟达和微软之前各自的系统相比,MT-NLG 的优点在于更加擅长各种自然语言任务,例如自动完成句子、问答、阅读和推理、词义消岐等。更重要的是,它甚至还可以在几乎不需要事先微调的前提下就执行上面所说的这些任务,这也被称为少样本或零样本学习。
然而,语言模型变得越来越大所带来的除了更强大的功能,还给开发人员带来了难题:模型越大,训练也更困难,尤其是 MT-NLG 的模型以及数据的训练,必须同时跨多个芯片来存储和处理,因此人工智能研究员和工程师也必须想出各种技术和技巧来训练它们,并进行调整。
这次 MT-NLG 使用了英伟达的 Selene 超级计算机进行训练,该系统由560个 DGX A100 服务器组成,每个服务器包含8个 A100 GPU。
以上所有这数千个 GPU 都使用 NVLink 和 NVSwitch 相互连接,每个 GPU 都能够以每秒113万亿次浮点运算的速度运行,训练这些模型的成本非常高。在这里,英伟达和微软的工程师使用了微软的 DeepSpeed 深度学习库,它包含 PyTorch 代码,允许工程师在多个管道中并行填充更多数据。
通过英伟达 Megatron-LM 和微软 DeepSpeed 的合作,工程师们创建了一个不仅高效而且可扩展的3D 并行系统,它结合了数据、管道和基于张量切片的并行性,从而能更好地应对大型模型带来的挑战。
英伟达公司加速计算产品管理和营销高级总监帕雷什·卡利亚(Paresh Kharya)和微软集团项目经理阿里·阿尔维(Ali Alvi)在博客文章中写道:“通过将张量切片和管道的并行性相结合,我们可以在最有效的情况下运行它们。具体来说,这一系统使用了英伟达 Megatron-LM 的张量切片来扩展节点内的模型,并使用了微软 DeepSpeed 的管道并行性来跨节点扩展模型。”

▲(来源:Pixabay)
举例来说,对于有着5300亿个参数的模型,每个模型副本跨越了280个英伟达 A100 GPU,在一个节点内具有8路张量切片和跨节点的35路管道并行性。接着,使用 DeepSpeed 的数据并行性进一步扩展到数千个 GPU。为了训练 MT-NLG,微软和英伟达专门创建了一个训练数据集,这一数据集主要来自 The Pile,数据集中包含了来自英语网站的2700亿个令牌。令牌在自然语言中是一种将文本片段分成更小的单元的方法,它可以是单词、字符或单词的一部分。与所有 AI 模型一样,MG-NLP 必须通过得到一系列示例来获得“训练”,从而学习数据点之间的各种模式,例如语法和句法规则。MT-NLG 的训练数据集的主要来源 The Pile,是一个由开源 AI 研究机构 EleutherAI 所创建的总共835 GB 大小的22个较小数据集的集合。The Pile 中的835GB 文本包含互联网上的各类资源,从百科到学术期刊存储库,新闻剪报到代码存储库等等。在为 MG-NLG 进行基准测试时,微软称当进行数学有关任务时,即使有些符号 “被严重混淆”,MG-NLG 也可以推断出基本的数学运算。而且系统不仅会完成普通的对算术的记忆的任务,还会主动完成那些题目中提示要求进行回答的任务,虽然 MT-NLG 还没有达到特别准确的程度,但这已经是自然语言处理中的一项很大的挑战。帕雷什·卡利亚和阿里·阿尔维在博客中写道:“这次在 MT-NLG 中所达成的质量和结果,是将 AI 的最大潜力应用与自然语言中所迈出的一大步。这次开发过程中 DeepSpeed 和 Megatron-LM 的创新不仅使得 AI 模型开发更强大,更使得大型 AI 模型的训练成本更低、速度更快。我们十分期待 MT-NLG 将进一步塑造未来的产品,并与开发者共同探索扩大自然语言处理(NLP)的界限。”
